The Many Forms of Deep, Audio-Driven Video Dubbing
Originally published on Medium.
Video Dubbing is the process of altering lip motions to match given audio. We explore some of the types of AI models that can do this.
The Many Forms of Deep, Audio-Driven Video Dubbing

Introduction
Audio-driven face dubbing, sometimes known is video dubbing, is an exciting development in the world of video editing, and it is made possible by the latest advances in deep learning. It is a process that allows for the synchronization of facial expressions and lip movements with the audio content, making it seem as though the person on screen is speaking the dubbed language. This technology is likely to be an essential component of the global film and television industry, enabling wider access to entertainment for people who do not speak the primary language of the content.
Dubbing has been a common practice for many years, but the issue of lip syncing has always been a problem. Dubbing is the process of adding audio of one language to video of another, but if the lip movements of the speaker do not match the new language, it can be jarring and break the immersion for the viewer. With audio-driven face dubbing, this issue is solved, and the viewer can enjoy the content without being distracted by the mismatched lip movements.
When it comes to audio-driven face dubbing, there are several methods that can be used to synchronize facial expressions and lip movements with the audio content. In this article, we will be breaking down some of the differences in the types of models that exist. In the future, we will cover many of the specific and state-of-the-art video dubbing methods using the distinctions in this article.
Person Specific & Person Generic
One of the biggest differences between audio-driven face dubbing methods is whether they are person-specific or person-generic. Person-specific models are designed to work for a single actor and are usually trained with data captured in controlled conditions. These models require a lot of data of the target actor in the same environment, but they can produce video that is almost indistinguishable from reality.
Person-specific models are often used for avatar creation, allowing for precise control over what the digital double of the actor is saying. This is the most popular form in the industry at the moment, for example the work of Synthesia, Deepreel, and D-ID. These models are designed to capture the unique facial expressions and lip movements of a specific actor and reproduce them in the dubbed version, providing a seamless match between the audio and video.
On the other hand, person-generic models are the holy grail of video dubbing. These models are designed to use a single reference frame and can match any video to any audio, making them ideal for use in films and TV. However, because they use only one frame, the quality of the output video can suffer, and the idiosyncrasies of the original actor cannot be recreated. A good example of this is the popular and open-sourced model Wav2Lip, which is incredibly versatile, but is far from photorealistic.
2D vs 3D Models
In addition to person-specific and person-generic models, another important distinction in audio-driven face dubbing is between methods that operate directly at the pixel level and those that use an intermediate 3D representation of the face.
2D models work by manipulating images at the pixel level. Typically, a neural network is trained to take three inputs: a masked version of the target frame with the lips removed, a reference frame containing the full face of the target actor to estimate the general shape and colour of the lips, and the audio to be used to reconstruct the lip shapes and mouth interior. Often these models will need to simplify the problem, relying on auto-encoders or else using warping methods to take pixels from the ground truth. One advantage of 2D models is that they can capture fine details in facial expressions and movements, particularly with the mouth interior such as the teeth and tongue, but they may struggle with changes in pose or lighting.
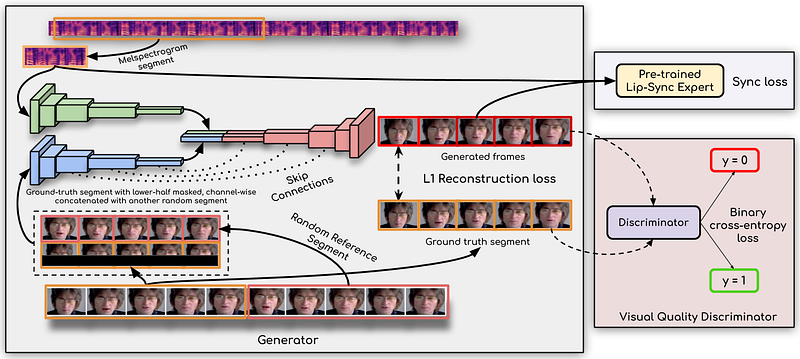
In contrast, 3D-based models use some form of 3D representation of the face, usually a 3D Morphable Model (3DMM). The 3D model has a small set of parameters, such as facial expressions like a smile or raised eyebrow. These models are fit to video, and a neural network called a neural renderer is used to recreate the real frames. Finally, a separate network predicts the 3D parameters from audio, which is a simpler task than generating pixels as the parameter space correlated to audio is usually small. This allows for more efficient and effective lip synchronization even with changes in pose and lighting. However, these models do not normally represent the teeth or tongue and often the final model is not able to manipulate these.
One example of a 3DMM can be seen in this demo from researchers at the Max Planck Institute for Informatics:https://flame.is.tue.mpg.de/interactivemodelviewer.html

Areas of the Face Targeted
Audio-driven dubbing models can target many different regions of the final video. In particular, there are three types of models in terms of the target:
- Lip sync only models: These target only the lower half of the face and the upper part of the neck. These models only aim to alter the lip motion, keeping upper face expressions from the target. This is the easiest approach, as the upper face region is only weakly correlated with the audio making it hard to synthesize. However, this can lead to clear discrepancies, for example a neutral audio being played on a face with a scowl.
- Full face models: These target the full face, including the upper half but do not consider pose. In order to model the upper portion of the face data must either be taken from a source actors’ video, or else synthesized using a generative model such as a GAN or diffusion model.
- Full head models: These models target everything, including the head pose. Head pose is even more difficult as its correlation to audio is even weaker, and issues like jitter are more noticeable. However, some models have begun to successfully synthesize head motion allowing for more expressive generated content.

Other Factors
There are many other factors to consider for audio-driven dubbing models. Some examples of these include:
- The explicit representation of stylistic features, in particular emotion: Models that do this enable users to adjust the emotional style of the output.
- Frame based or video based: Frame based models generate one frame at a time, this is a much easier task, but can lead to temporal inconsistency in the final videos.
- Runtime: Models can range from working in real-time, for applications such as video calls, to taking several days to produce short video clips, which may be useful for high-end films.
Conclusion
In this article we have discussed some of the many different dimensions of audio-driven video dubbing. In the future, we hope to cover many of the individual methods in greater detail, using some of the distinctions laid out in this article. If there is any you want covered in particular, please let me know either in the comments, or by sending me an email!
By Dr Jack Saunders on April 20, 2023.
Exported from Medium on March 18, 2026.