Breaking Down Synthesia 2.0
Originally published on Medium.
We take a look at the tech that’s underpinning the impressive new launch.
Breaking Down Synthesia 2.0
We take a look at the tech that’s underpinning the impressive new launch.
So Synthesia just launched v2 of their avatar product, and a lot is happening. From the ability to automatically translate between languages to the full generation of 3D bodies including hand gestures. But most relevant from my perspective is the improvement in face generation. It’s a pretty big leap, but to be honest, it is clear this has been coming for a while. Researchers associated with Synthesia have been pumping out papers at a dizzying rate (and good quality work too). Look at Matthias Nießner’s publications page—14 papers at this year’s CVPR (!!). Using these papers, plus my knowledge of the avatar space, I will break down how Synthesia 2.0 likely works. This article covers a lot of heavy research and so is both too dense(covering a lot of work in a small space)and too sparse (missing out some details) but it serves as a good reference point for an understanding of how this complex tech may work.

Disclaimer: This article is written using my best guesses only. I do not have any internal knowledge about Synthesia’s tech pipeline. Please seek legal advice before trying to use any of the following in your own commercial work.
PS: If you like the look of this product, please consider signing up via my link here.
New Face Model
We’ll start with the most important part of the digital avatar, and the part that is closest to my own area of expertise — the face. In the past, as I have discussed, Synthesia has made use of a 3DMM pipeline. Based on the list of publications associated with the company, I think the pipeline is still similar, but with all the relevant components upgraded. Recall that a 3DMM pipeline has 4 components:
- The 3DMM itself — In many cases this is FLAME.
- The tracking of the model to video data.
- The control of the model with an audio signal.
- The generation of photorealistic video from the modified 3DMM.
Indeed each of these 4 components has an associated paper.
3DMM → NPHM
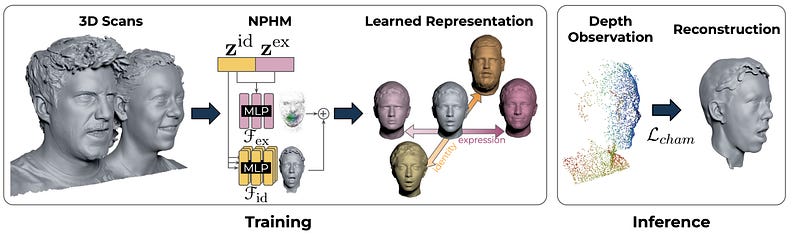
Let’s first look at the new form of 3D Morphable Model that forms the base of v2. A 3DMM is a statistical model of shape and sometimes appearance which has a set of parameters to control it. A good example and the most common in the field is FLAME. Take a look at the viewer here to get a feel for one. Of course, there are some serious drawbacks to such a model. The most obvious of which is a serious lack of fidelity. In the diagram below, FLAME is on the left. It does not capture fine-grained detail.
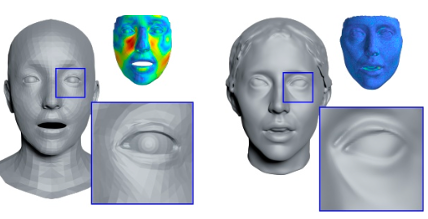
NPHM addresses this problem by using a different representation of Geometry — SDFs. SDFs are Signed Distance Functions. A neural network is trained to take a point in 3D space and to predict how far it is from the surface. If the point is inside the mesh it has a negative sign, if it is outside it has a positive sign. This is advantageous as, unlike meshes it does not rely on any specific topology, meaning it can model shapes in arbitrary detail.
NPHM is built upon face scans (over 5200), consisting of points in 3D space. One could imagine building an SDF for each scan by training a neural network to predict the distance between any point in 3D space and the nearest point on the 3D scan. However, a single SDF is also not useful in the same way as a 3DMM. Instead, we want to learn a parametric model of SDFs.
In the following, I am going to grossly oversimplify. If you’re interested in implementing the work, I suggest you readthe paper.
Let’s first assume we have a perfect representation of identity in the form of a latent vector z. We could take an MLP to define an SDF and condition it on this latent vector in such a way that the resulting SDF would represent the geometry of the given identity. But how can we do that? One idea that springs to mind is to train an auto-encoder. Given a subject’s scan S, we could use a network to predict zand decode with our SDF. Unfortunately, this does not work. In practice, the point cloud scans have arbitrary topology and differing numbers of points. This means they are not well suited to an encoder architecture. Instead, what is done in the paper is to train an auto-decodermodel. Each identity latent vector is initialised randomly and jointy trained with the SDF decoder. I show the difference below.

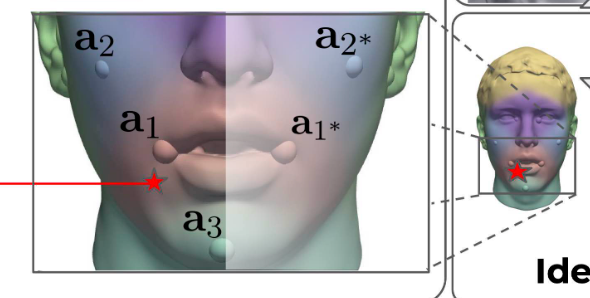
While this works, it relies on only a single MLP to represent the whole face. This is a difficult problem as the face is very complex. NPHM breaks the problem down into smaller subproblems by representing the face as a collection of smaller MLPs centred around specific anchor points. These anchor points are the usual facial landmarks (e.g. lip corner, nose tip, outer left eye etc). These are then combined to give an overall SDF of the face. Furthermore, facial symmetry is exploited by having weights shared between MLPs on each side of the face. For example SDF(Left Eye) == SDF(Right Eye).
The method described above produces only faces in a canonical pose and expression, in this case, a neutral face with the jaw open. This pose is obtained directly in the scans. We also need a way to model expression. This is done with an additional MLP that is conditioned onboth expression and identity.This is different from FLAME, where the expression basis is independent of identity, and allows for idiosyncratic (person-specific) details to be captured. For example, how I may smile differently to you. 23 FACTS-based expressions are captured for each subject and these form the expression basis, meaning that the model has semantic control.
There is a lot more going on in this paper, including the loss functions, data capture setup, prediction of landmarks and method of combining latent identity vectors. But for now, let’s assume we have a model that can take a latent vector for identity Z_id and one for expression Z_exp and then tell us if a point x is inside or outside the surface of the face, and how far away it is. This is the 3DMM equivalent in the pipeline.
Fitting NPHM’s to Video
Now that we have a parametric model that can serve as a prior, we need a way to fit it to an input video. There are actually a couple of papers doing this, including one that very cleverly uses a diffusion model as a prior for regularisation to fit to depth maps. However, the most relevant for our purposes is MonoNPHM, a method for fitting colourised NPHM’s to RGB video.

If you’ve read my previous article on fitting a 3DMM to a video, you’ll likely understand this paper well. A combination of losses including a 2D landmark loss, a photometric loss and regularisations are used. There are a few issues, however, that stop this from being a straight swap from 3DMM to NPHM.
First, let’s consider appearance. The above NPHM contains no information about the colour of the face. To include colour information, we might consider adding another latent code Z_app and an MLP that predicts colour for any point in the canonical space. This has its issues though. The appearance information is independent of the geometry and may produce inaccurate results. To overcome this, the MLP does not take the point x in 3D space, but instead the output of the final feature layer of the geometry MLP for the SDF. This allows the two to share information improving the tracking.
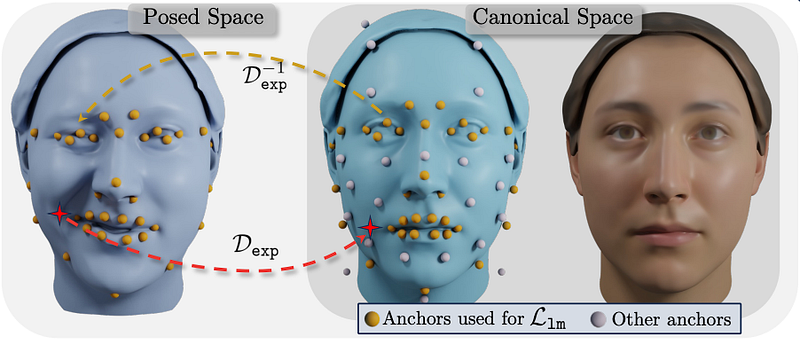
For landmarks, the small handful used in the original paper is not enough. Thankfully, the solution here is pretty straightforward. More landmarks are selected and the NPHM model is retrained using a total of 65 (matching the 65 used in the 2D landmark detection module). As using 65 MLPs would be over-constrained, each point in 3D space is evaluated using only the 8 closest landmarks.

In 3DMM-based works, differentiable rasterization allows for backpropagation of gradients for optimization. This does not work for NPHM, which instead relies on volume rendering with ray sampling. Lighting is achieved with Spherical Harmonics as it is with 3DMM’s, the difference being that normals need to be computed per sampled point.
From here, the losses are pretty similar to 3DMM-based work. An RGB loss, landmark loss and silhouette loss are all used. Regularization is applied on each latent vector and temporal regularisation is also used at the level of latent expression vectors, as well as the global pose. It is worth noting I have skipped some parts of this work involving forward and backward deformation fields. I have done this for brevity, but I recommend reading about them in the MonoNPHM paper.
Driving NPHM from audio
The next stage is to drive the NPHM model from audio input. Again, there is a paper with this as its focus. The paper is called FaceTalk.

FaceTalk shares a lot of similarities with older speech-to-mesh animation models such as Imitator and FaceFormer. FaceTalk aims to operate at the latent space level, rather than the vertex level. In order to produce realistic and diverse animations, a diffusion transformer is used. I covered a bit about diffusion transformers in my previous post on scaling lip-sync models. In essence, a diffusion process is trained over sequences of expression latent vectors. Noise is added and a transformer learns to predict and remove that noise. Like previous work, the transformer is also shown per-frame audio representations using wav2vec2. These are passed to the transformer using cross-attention layers.
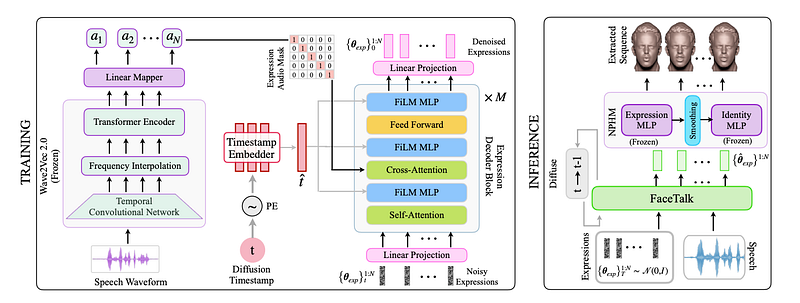
Compared with pure regressive methods such as the previous state-of-the-art, the generated animations are much better. We found a similar result with GANs in our previous work READ Avatars.
Getting Photorealistic Video
Finally, given an NPHM controlled by audio, we need a way to convert it back to photorealistic video. There are a few potential options for this, but the highest-quality models are based heavily on Gaussian Splatting. I have a summary of all of the early Gaussian Splatting papers for photorealistic head avatars that is well worth a read, but I’ll cover the two that I think are serious candidates for Synthesia 2.0.
NPGM
The first of these models is Neural Parametric Gaussian Avatars (NPGM). This paper is notable in my opinion for two reasons. It combines many of the features of earlier Gaussian Splatting head avatar papers, taking the best of each, and it applies the methodology to NPHM models rather than just explicit geometry models, which had previously been a limiting factor.

Like most Gaussian avatar papers, this works by attaching Gaussians to the surface geometry via a canonical mesh. Gaussian attributes are learned in a canonical space and are posed using the transforms of the underlying mesh (or in this case NPHM). These are also augmented using a small MLP conditioned on the latent vectors Z_exp, an idea from earlier papers.
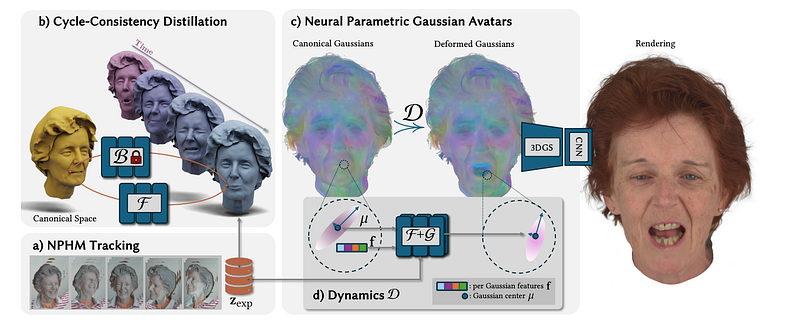
To further improve the quality, a screen space CNN is used. This just means that an image-to-image network is applied after rasterization. These steps, in addition to a better densification strategy, allow for really high-quality output (seriously, look at the project page!).
The key to getting this to work with NPHM is in learning a forward mapping from the canonical SDF to the posed space. In the tracking and audio-driven sections, only the backward deformation is learned. To get the forward deformation field, a cycle consistency loss is used. That is, a point to deformed using the learnable forward deformation, and then “undeformed” using the frozen backward deformation. The point should be back where it started, so this is used as a cycle consistency loss.
Diffusion Avatars
The other option, and more likely in my opinion is Diffusion Avatars. This work uses stable diffusion, controlled using a ControlNet. This is in keeping with the larger theme in faces, and machine learning as a whole, to use large pre-trained models as a way of generating ultra-high-quality outputs.

This paper shares some similarities with deferred neural rendering. Instead of a learnable neural texture, the NPHM models are rasterised with a learnable feature function. This is defined using a triplane (e.g. each point is decomposed into its projection on the xy, yz, and xz axis) and therefore has a learnable feature at each point in space. In addition to these features, a correspondence map (like a uv texture map), depth and normals are also rendered. These are concatenated into a many-channelled image which is used as input to a ControlNet which adapts the pre-trained stable diffusion.
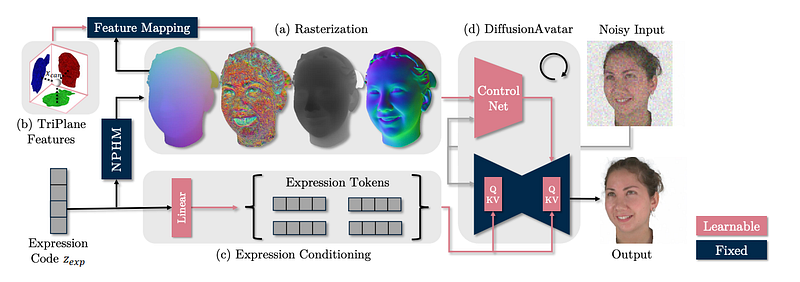
This can be thought of as deferred neural rendering but with NPHM in place of a 3DMM and the image-to-image network using the insanely powerful prior of Stable Diffusion. Given that Synthesia v1 was built on Deferred Neural Rendering, I think it is likely that v2 is built upon its much more advanced counterpart.
Body Model
In addition to all the improvements to the face model, Synthesia 2.0 also offers control over the arms and hands. It is now possible to generate gestures for the first time. We’re a bit out of my wheelhouse here, and the research being output is more limited. But still, we can make some pretty reasonable guesses about how it works. As this article is already too long, I’ll give a very brief overview of the existing work.
If you want more please let me know and I may cover it in more detail in the future.
Data
The major hint that Synthesia was considering launching a model including the full body is in the release of the first and only research work to be officially branded as Synthesia research. This is HumanRF, which includes the ActorsHQ dataset. It consists of multi-camera captures of 16 subjects showing the full body. This data is invaluable in building body models. It’s also a safe bet that Synthesia didn’t spend several million dollars on a capture rig just for a 16-person, open-source dataset. They almost certainly will have captured data of a few hundred to a few thousand people.

NPM
NPM — Neural Parametric Models is a very similar method to NPHM which predates it. This means Synthesia can build a model for the body just like the one for faces. They also have the data to do this.
Generating Gestures from Speech
I’ve not seen enough detail to have much confidence about how the gestures are generated. It may be as simple as pre-recorded gestures being re-targeted to the desired body representation and added as needed. However, there are a few papers that look at generating gestures (in the from of sequences of joint positions from audio). For instance, RecMoDiffuse and TalkSHOW. The former is from Lourdes Agapito’s group. Lourdes is a co-founder of Synthesia.
Creating Photorealism
Just as with faces, there are several options for how the now-controlled geometry may be converted into photorealistic video. If I had to guess, Gaussian Splatting is involved. Several papers have looked to create photoreal, animatable avatars with Gaussian Splatting. See Mr NeRF’s Gaussian Splatting GitHub repo for an updated list. Of particular relevance is “HAHA: Highly Articulated Gaussian Human Avatars with Textured Mesh Prior” from Lourdes’ group. While this uses a mesh, it can be imagined that it may be extended to other geometry representations.
What’s Next
There can be no doubt that Synthesia 2.0 is the culmination of a lot of fascinating and complex work, and the results are pretty awesome! That’s not to say, however, that it is without issues. From my short time viewing some of the newly generated videos, one flaw in particular stands out - the hand gestures created so-called self-intersections. This is where one hand passes through the other, creating some weird artefacts.

I expect that the team will be very much aware of this and they’ll be working to improve on it. Some recent work outside the group has looked at penalising self-intersections with an energy function, or else the solution may lie in physics-based Gaussian Splatting.
Another direction I believe Synthesia is considering is creating a generative model of 3D avatars. Instead of requiring a user to select an avatar or film themselves, it would be cool if they could create an entirely new avatar. The work from Matthias Nießner’s lab “GGHead: Fast and Generalizable 3D Gaussian Heads” does just this. Using a modified GAN, they are able to randomly sample static Gaussian head models. If this were to be combined with some of the above methods, you could imagine creating fully animatable Gaussian avatars from scratch.

Even better than creating random samples, you could imagine a text-to-avatar system. Suppose you have a generative model like GGHead, it could be combined with a text encoder, like CLIP and used to create Gaussian avatars from a text description.
If I were a betting man, I would bet on a text-to-avatar system, which takes a short description and creates a fully animatable avatar with TTS control and gestures, being the next release from Synthesia.
Conclusion
The release of Synthesia 2.0 is impressive, and the tech behind it is deep and complex. Given the recent publications from Synthesia and their related researchers, we can hazard a good guess of what’s going on under the hood. We have covered, at a very high level, what the tech might be. Of course, the ability to create such lifelike avatars comes with a series of ethical questions. I have discussed these in some of my previous articles. While there are some small issues with the model, it’s still a big step forward and I think we can expect more exciting developments in this space!
By Dr Jack Saunders on June 24, 2024.
Exported from Medium on March 18, 2026.